Web Scraping & Visualization — Project Report
Summary
This project implements an end-to-end pipeline to collect, store, and visualize publicly available video-ranking data from a major online video platform. The aim was to explore geographic differences in popularity, track trends over different time windows (daily, weekly, monthly, yearly, all-time), and build a robust system that runs on a schedule with monitoring and backups.
Note: the project only collects information that is publicly visible on the website and uses rate limiting and scheduling safeguards to avoid overloading the site. See the Ethics & Legal section for more details and a summary of precautions taken. In addition since August 2025 this project has stopped due to changes on the site that reduce the data collection and insight significantly and I was ready to move on.
Inspiration
One of my favourite authors Sir David Spiegelhalter wrote many great books about statistics. So one day I went through all of his book list and one stood out to the 18 year old me at the time - you may see why.

This was Spiegelhalter’s first - and probably worst - book he wrote but it grapped my interest and I thought it would be interesting to collect data from a popular adult video content site. That is what I did and I collected data for over 2 years and in the end. I also started creating a limited site that was decent enough for me to publish my data. I decided to stop in the Summer 2025 to due the desire to move on to different project and the site going through significant changes that limited the insight one could gain from it.
My role
I developed and maintained the full pipeline:
- Designed the scraping logic and navigation (R + RSelenium).
- Implemented parsing and structured extraction for titles, views, like-ratio, durations, URLs and metadata.
- Built a lightweight maintenance/monitoring workflow (Python) to notify me when the pipeline fails and to manage backups.
- Created the visualizations and basic analyses used for exploratory reporting.
Tools & Technologies
- R: RSelenium, rvest, openxlsx, readxl, httr, netstat, wdman, binman
- Python: automation & maintenance scripts (notification + CI integration)
- Data storage: .xlsx backups, local/OneDrive sync
- Version control: Git (repository for code and visualizations)
- Visualization: (R plotting libraries / Python alternatives — specify in repo)
Data collected
For each country and time window the scraper extracts up to 30 entries with the following fields:
date— scraping datetitle— video title (cleaned)views— number of views (raw string)likeRatio— like / dislike summary (raw string)duration— video durationURL— fully qualified link to the videofeaturedOn— channel or uploader infocountryID— two-letter country code (orworld)mostViewed— the window used (today,weekly,monthly,yearly,allTime)position— rank position for that listMorningOrEvening— a flag for time of scraping (optional)
The scraper cycles through 31 country codes (plus a global world listing) and collects categories selectively to reduce unnecessary requests (for example all-time is collected monthly).
Implementation details (high level)
Architecture & flow
- Bootstrap (R) —
LoadingPH()sets up RSelenium (browser driver), navigates the site, and handles consent dialogs (e.g., the “I am 18+” button and cookie prompts). - Loop over countries & windows — for each country code the script visits the appropriate URL for
today,weekly,monthly,yearly, orallTime(controlled by date logic to reduce frequency). - Parse HTML —
Readinghtml()reads the page source and extracts the 30 top videos using XPath selectors for title, views, likeRatio, duration, url and uploader. - Append & save — new rows are appended to the master Excel file and a dated backup is created.
- Monitoring & maintenance (Python) — when the R script fails due to structural changes or connectivity issues, a Python script posts a notification (WhatsApp Web in this case) and provides logs for debugging.
Key implementation notes
- The parser relies on XPath and CSS selectors. Because websites change frequently, the code includes fallback XPaths and
tryCatchlogic to handle common variations in structure. - A randomized sleep (
runif(25, 45)) between requests reduces server load and the risk of being rate-limited or blocked. - Only publicly-available metadata is collected — no authentication, scraping behind paywalls, or attempts to retrieve user-private data.
- Backups are stored under a dated directory with both a main Excel file and daily backups for recovery.
Ethics, legal & safety considerations
- Public data only: The scraper collects information that any visitor can see on the platform’s public pages. It does not attempt to access private pages or user account data.
- Rate limiting: Randomized delays between requests and limited-frequency scraping for low-variance endpoints (monthly/yearly/all-time) mitigate the risk of server overload.
- Robots & ToS: Before scaling or deploying the scraper, verify the target site’s
robots.txtand Terms of Service; some websites explicitly disallow automated scraping. If required by policy, obtain permission or use an official API. - Content warning: The project scrapes adult content metadata. Consider removing or obscuring explicit titles on public-facing pages or using content warnings on your portfolio site to respect readers and recruitment reviewers. This warning goes out if you want to look at the data collected.
- Privacy & compliance: If you ever scale this work or use scraped data for analysis/publication, ensure compliance with relevant laws (e.g., GDPR for storing personal data) and platform policies.
Maintenance & monitoring
- Failure detection: I built a lightweight notifier (Python + WhatsApp Web) which sends a message if uploads fail or unexpected HTML changes occur.
- Versioning: Code and data artifacts are tracked with Git. Store credentials and sensitive files outside the repository (use environment variables or secrets management for production).
- Recovery: Daily backups are kept locally/OneDrive to allow quick restoration.
- Operational checklist: Include a short checklist in the repo README for how to re-run the scraper and where to look for common fixes (changed XPaths, consent dialog moved, driver updates).
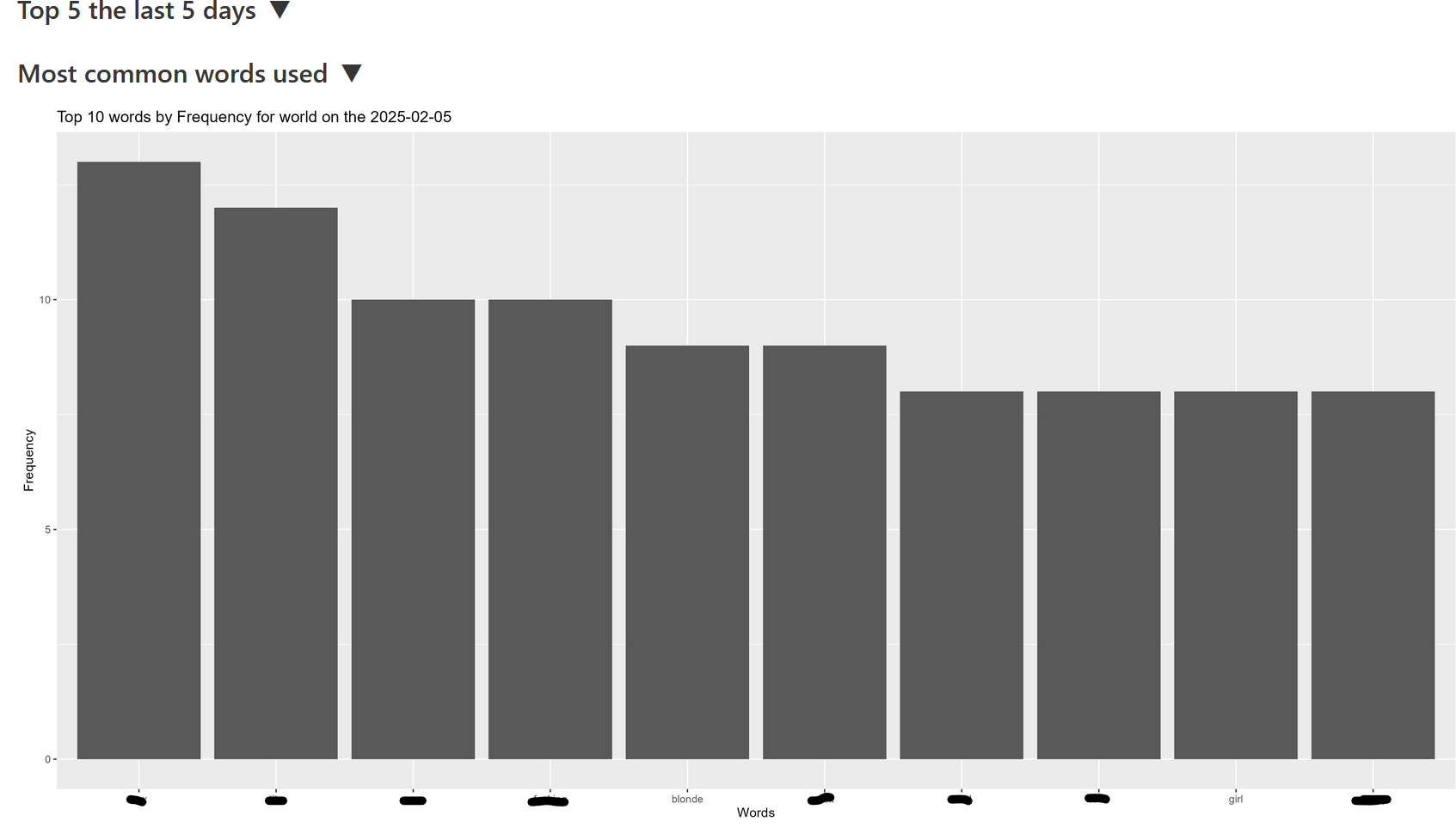
Visualizations & analysis (examples to include in the repo)
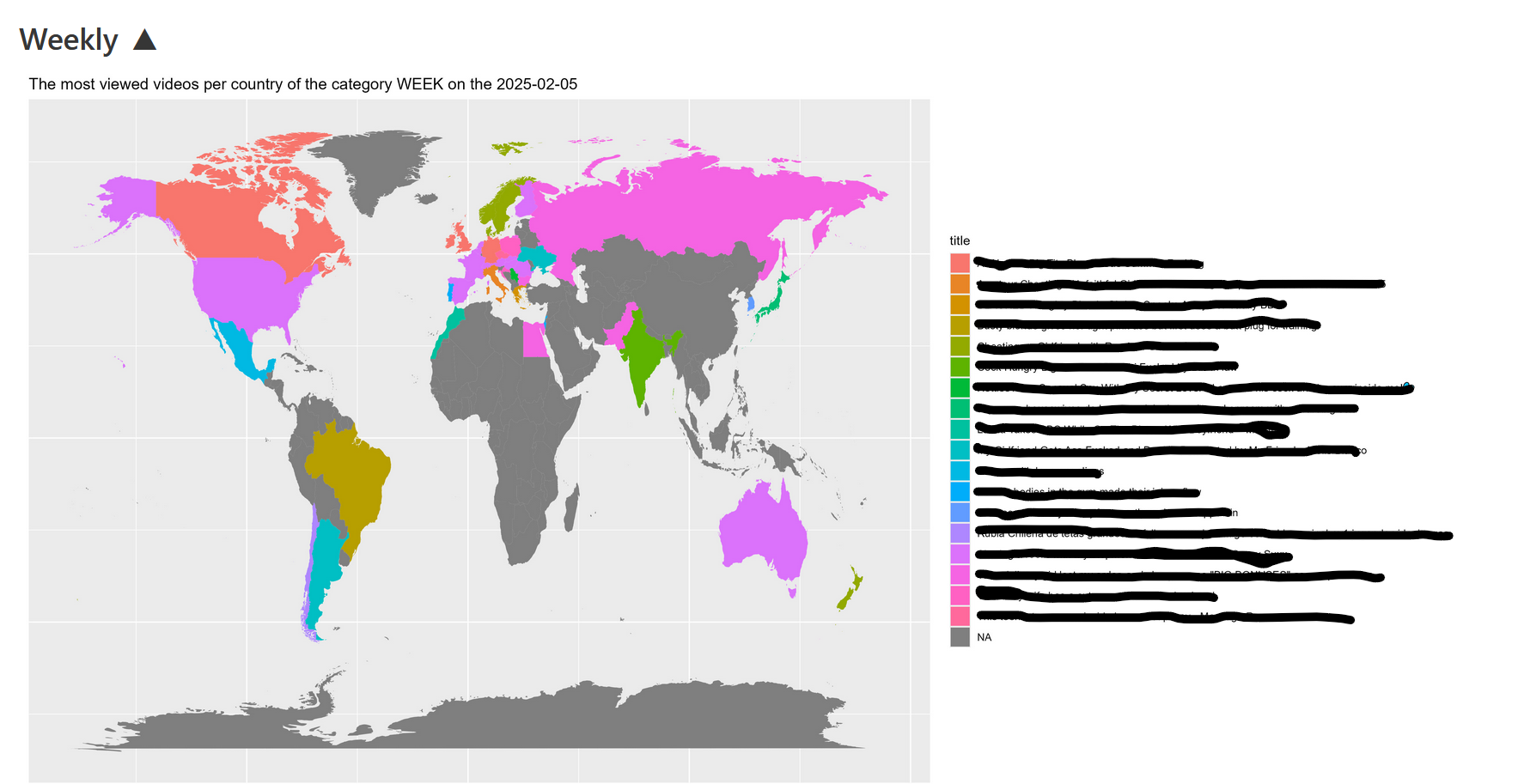
- Country-level leaderboard maps (choropleth) showing top video counts or aggregate view counts.
- Time-series for a sample country showing daily/weekly trends for top videos or genres.
- ROC-like charts for classification of genres or uploader categories (if applicable).
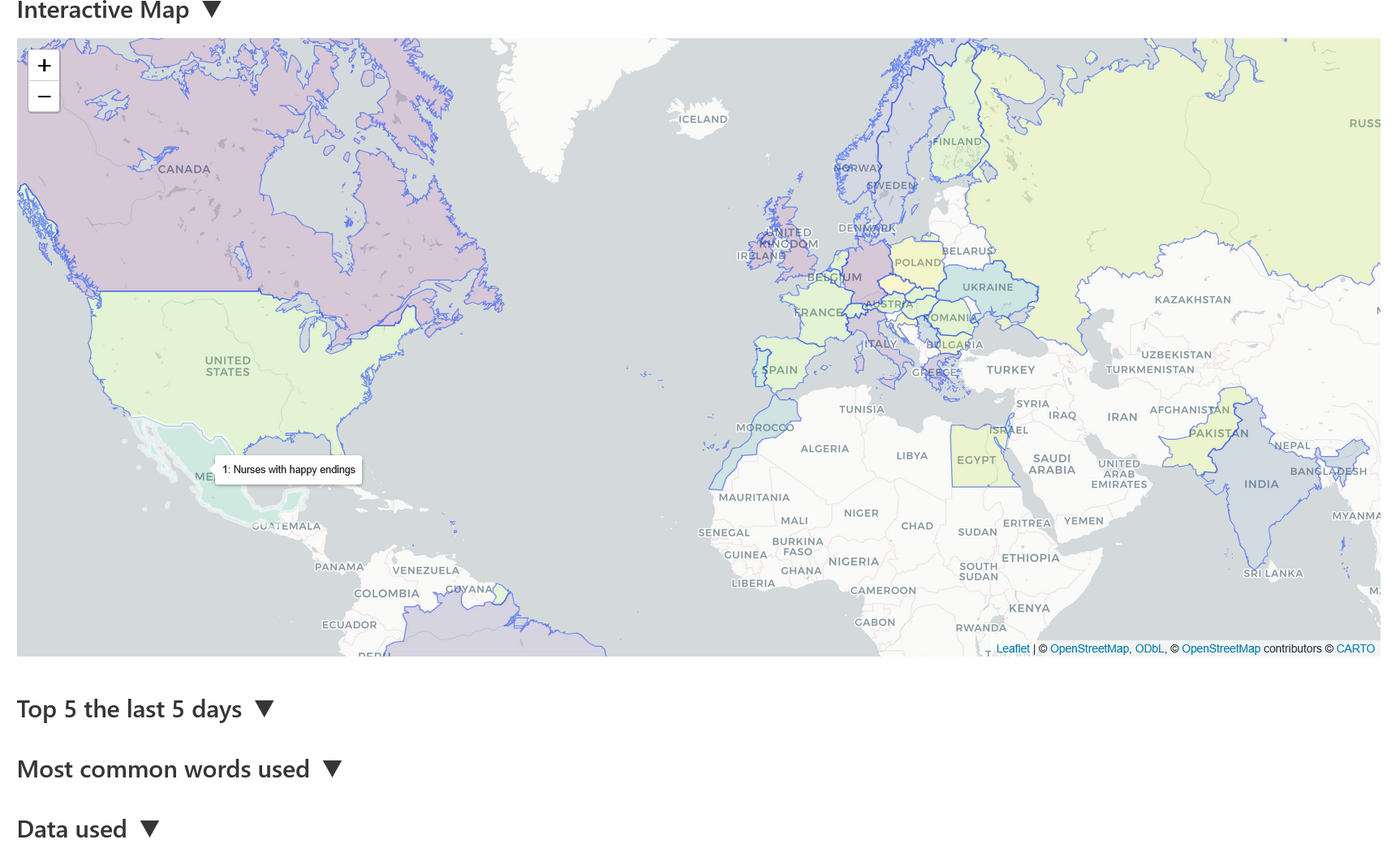
- Interactive dashboards (Plotly/ggplotly or Shiny) to let reviewers explore country/time windows.
Limitations & future work
- Fragile selectors: XPath/CSS scraping is brittle to front-end changes. A more robust approach is to use official APIs (when available) or to implement resilient parsers that detect layout changes automatically.
- Data normalization: Many fields (views, like ratios) are scraped as strings. Parsing these into numeric types and normalizing locale-specific formats improves analysis quality.
- Storage & scale: Move from flat Excel files to a structured database (Postgres, BigQuery) for scalability and versioned analysis.
- Testing: Add unit tests for parsing routines and a small integration test that validates a known page snapshot.
- Ethical improvements: Add an explicit content filter and a configurable public-facing view that anonymizes sensitive strings before publishing.
How to present this on a portfolio site
- Create a short blurb (3–4 lines) focusing on the problem, approach, and impact.
- Add a screenshot of one or two visualizations and a link to the code repository (private link OK, provide sanitized sample data).
- Provide a short technical appendix in the repo (README) listing how to run the scraper and common fixes for maintenance.
- Include the content warning near the top so recruiters can opt out if they prefer not to view explicit material.
Skills demonstrated
- Web scraping with RSelenium and rvest
- Handling production issues (browser drivers, consent dialogs, changing HTML)
- Building a monitoring and backup strategy
- Data cleaning, ETL, and visualization
- Cross-language automation (R + Python)
Webscraper Code
Daily Update Script
import os
import time
from time import gmtime, strftime
import pywhatkit as p
import pyautogui
from datetime import datetime
import keyboard as k
while (True):
# note one hour behind
if (strftime("%H:%M", gmtime()) == "13:30"):
print("It works")
newUpdate = False
os.system("git add .")
if(os.system("git commit -m'MorningDailyUpdate'") != 1):
newUpdate = True
if(newUpdate):
#print("We get here")
now = datetime.now()
hour = int(now.strftime("%H"))
min = int(now.strftime("%M"))
p.sendwhatmsg("+44 xxxxxxxxxxx","Morning update complete with out any issues", hour, min + 2)
pyautogui.click(1050, 950)
time.sleep(2)
k.press_and_release('enter')
time.sleep(60)
pyautogui.hotkey("alt", "f4")
else:
now = datetime.now()
hour = int(now.strftime("%H"))
min = int(now.strftime("%M"))
p.sendwhatmsg("+44 xxxxxxxxxxx","ERROR with: Morning update", hour, min + 2)
pyautogui.click(1050, 950)
time.sleep(2)
k.press_and_release('enter')
time.sleep(60)
pyautogui.hotkey("alt", "f4")
time.sleep(60)
os.system("git add .")
os.system("git commit -m'MorningDailyUpdate'")
os.system("git push")
Web-scraper + Visualizer Code
https://github.com/HerrNiklasLange/Webscrapper-PH
The site
The site has been taken down but it was a basic site. I added some screenshots below what it looked like.
The site was updated on a daily basis from 2023 till 2025