What is this
This is the final project I did with 3 other students, even though I was the only undergraduate in the group I have done well and I am happy to present the following code.
This was done while I was studying at Michigan Technological Universities (MTU)
The Team
I do not deserve credit alone for the final report and the work. This was a team project and I am thankfull to have the following people on my team and they should receive the same credit as every member of the team:
- Amirmehdi Moghadamfarid, amoghad1@mtu.edu
- Samuel Raber, sjraber@mtu.edu
- Eric Fosu-Kwabi, efosukwa@mtu.edu
The Project: Hierarchical Reinforcement Learning Fraud Detection (HRLFD) - an Adapttive approach
Introduction
Financial fraud detection is a critical task in the modern digital economy. Traditional supervised methods often struggle with imbalanced datasets, where fraudulent transactions are far less common than legitimate ones. This project explores the use of reinforcement learning (Q-learning) combined with decision tree classifiers to detect fraudulent cases more effectively. The goal was to design and evaluate a hybrid model capable of identifying fraud while minimizing false negatives.
Methods
Data Preparation
- Resampling with SMOTE was applied to address class imbalance.
- The dataset was shuffled to prevent ordering bias.
- Features were used both in isolation (for decision tree models) and collectively (for Q-learning).
Reinforcement Learning (Q-Learning)
- States: Individual data points from the resampled dataset.
- Actions: Predict fraud or not fraud.
- Reward function:
- +6 for correctly identifying fraud,
- +8 for correctly identifying non-fraud,
- –10 for false negatives (missing fraud),
- –9 for false positives.
- Training loop: Up to 1000 episodes with early stopping based on F1-score.
- Exploration strategy: Epsilon-greedy, with epsilon decaying every 100 episodes.
Decision Tree Models
- A decision tree classifier was trained for each individual feature.
- Predictions were aggregated to form a “lower-level” ensemble.
- This ensemble provided candidate fraud cases for further evaluation with the Q-learning model.
Evaluation Metrics
- Accuracy, precision, recall, F1-score.
- Confusion matrix to visualize class distribution.
- ROC curve with AUC to assess trade-offs.
Results
- Q-Learning Model:
- Achieved strong recall, prioritizing fraud detection over overall accuracy.
- F1-score improved steadily during training before stabilizing.
- ROC curve showed strong discriminatory power (high AUC).
- Decision Trees:
- Individual features often produced misleadingly high R² values due to class imbalance.
- When combined, they offered useful fraud candidate indices, but with lower standalone accuracy.
- Hybrid System:
- Decision trees helped pre-filter suspicious cases.
- Q-learning provided better performance on fraud prediction than standard decision trees alone.
Hybrid results
Unique predictions: (array([0, 1]), array([69523, 4056]))
Class
0 71101
1 2478
Name: count, dtype: int64
Precision = 0.6065
Recall = 0.9927
F1 Score = 0.7530
Accuracy = 0.9781
Accuracy for true fraud cases = 0.9927
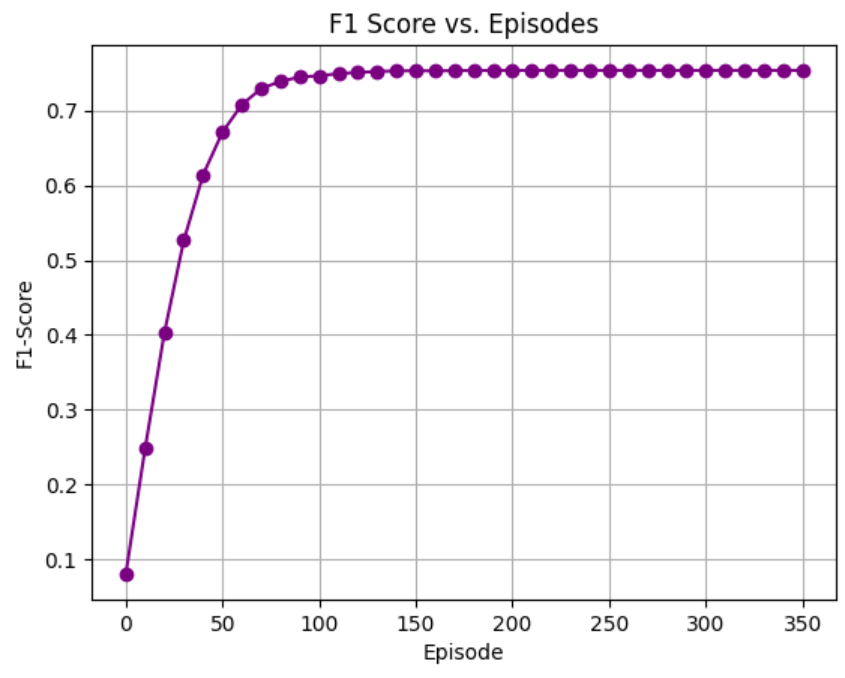
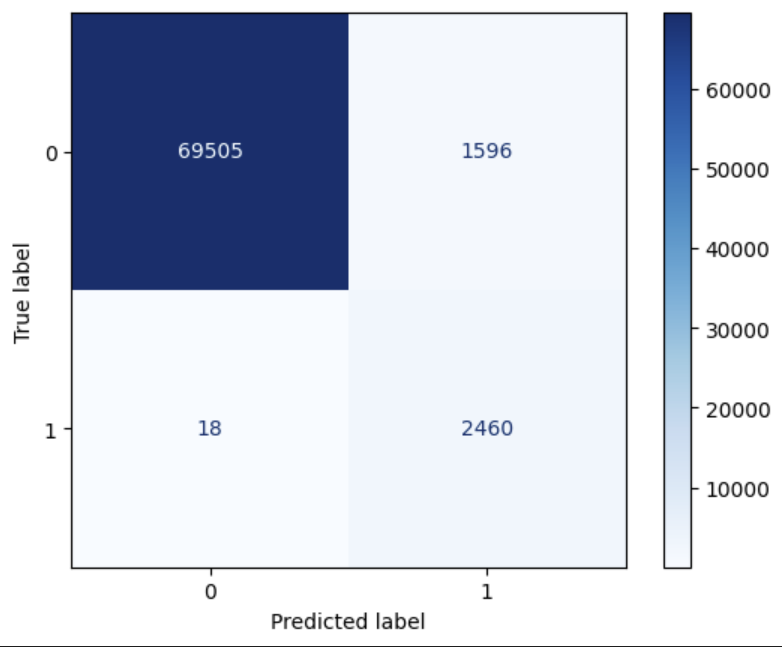
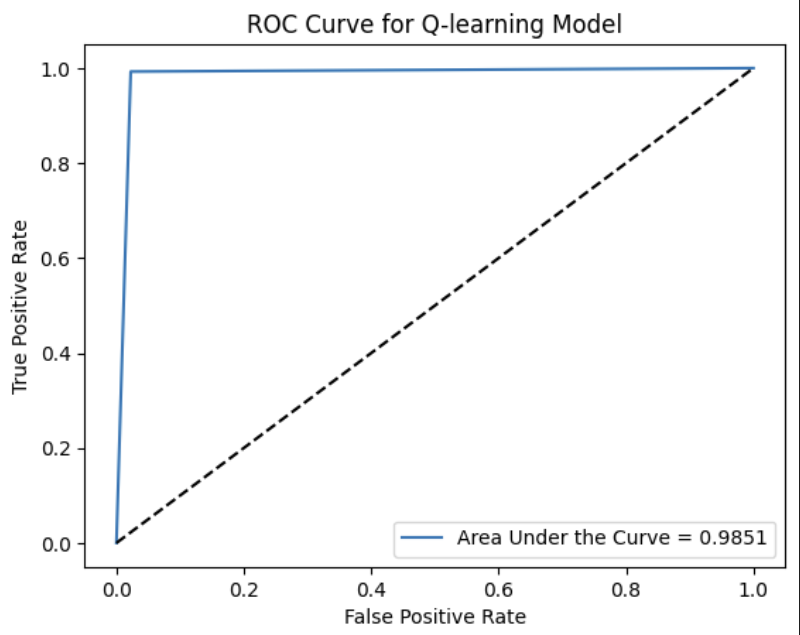
Discussion
The reinforcement learning approach demonstrated clear advantages in prioritizing fraud detection. False negatives (missed fraud) were heavily penalized in the reward function, leading the model to err on the side of caution. While this lowered the overall accuracy due to false positives, it better reflects real-world priorities, where catching fraud is more important than occasionally flagging a legitimate transaction.
Conclusion
This project highlights the potential of reinforcement learning for fraud detection, especially when paired with traditional supervised models. By experimenting with a reward-driven framework, the model was able to achieve high recall and balanced F1-scores despite data imbalance. Future work could include:
- Testing on larger or real-world datasets.
- Exploring deep reinforcement learning approaches.
- Fine-tuning the reward function to balance recall and precision more optimally.
The code
The code for the project: https://github.com/HerrNiklasLange/HRLFD/blob/main/Final_Project_Code_Red.ipynb